Use the Sensitivity Specs panel to enable sensitivity analysis and to specify the variables you want to use for it. For more information on sensitivity analysis, see performing sensitivity analysis.
To open the Sensitivity Specs panel click on the Model Analysis Tools ![]() tab of the properties panel (with nothing selected in your model). Then click Sensitivity on the tabs that appear at the top.
tab of the properties panel (with nothing selected in your model). Then click Sensitivity on the tabs that appear at the top.
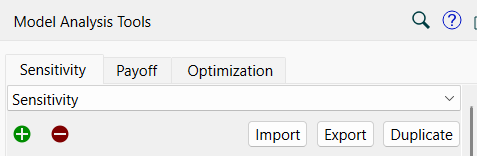
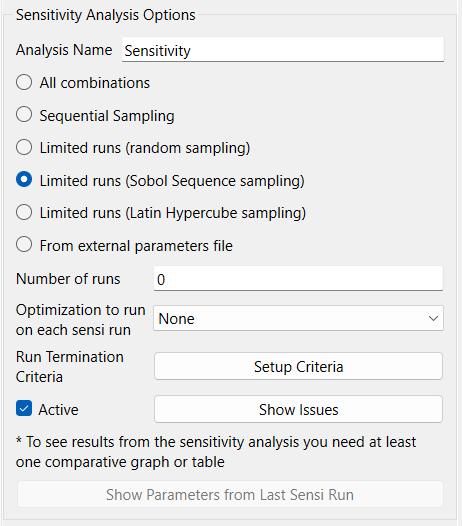
You can have one or more Sensitivity definitions. By default, the first is called Sensitivity, but you can change this name.
The name appears in the dropdown. If you have defined multiple sensitivities, use the dropdown to select the one you want to edit. Use ![]() to add a new sensitivity definition and
to add a new sensitivity definition and ![]() to remove the current definition.
to remove the current definition.
Import, Export, Duplicate allow you to save copies of the current specs for use in other models, or to edit directly. Export will write the specs to an xml files you choose. Import will bring in a set of previously exported specs. When they are brought in they will be added to the end of the list of specs. If nothing is imported you will see a message. Duplicate creates of duplicate of the current specs, and adds them at the end.
Note Import will only import sensitivity specs. If you have exported payoff or optimization specs they must be imported from their respective panels.
This uses the settings for each variable to determine the total number of runs. For each of the parameters the values are determined, then all combinations of those values are used. The total number of runs is the product of the number of runs for every different parameter.
This uses the settings for each variable to determine the total number of runs by adding them up, then adding 1 for a run where all constants are left at their base value. Instead of changing constants in combination, it will make changes for the first entry, set those back and make changes for the second entry and so on. Sequential sampling is a good way to test all constants in a model to see which impact behavior. Typically each constant would use an incremental distribution with two values. This can easily be set up by selecting multiple variables when adding a parameter as described below.
This lets you specify the total number of runs directly. For more information on specifying the number of runs, including information on Ad Hoc and Incremental distributions, see Selecting Sensitivity Analysis Distributions.
Sobol Sequences are designed to explore as much of the n dimensional parameter space as possible. They are not actually random, but instead provide a sequence of numbers that has some of the characteristics of a continually refining grid search but with much higher efficiency. They can provide the same sampling coverage you could get in a purely random sampling in many fewer simulations. Put another way, the same number of simulations will provide much more complete coverage.
In Latin Hypercube points are drawn without replacement from the distributions of each of the input variables. This guarantees that the full range of the distribution will be sampled for every parameter and, with the exception of incremental and ad-hoc inputs, there will be no repetition of the ranges. This allows you to achieve the maximum variation (of each parameter individually) with the minimal number of simulations.
From External Parameter File, if checked, will bring in a sequence of values for different parameters from a file. Once checked, there will be browse button to choose a file:
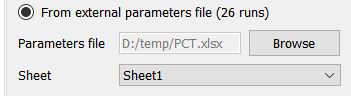
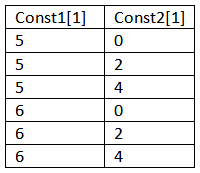
If the file you choose is an Excel file you will see a dropdown for the sheet to use. The input format is the same as it is for all import files with a list of full subscripted variables names in the first row or column and a series of values in the associated column or row. For example:
If parameter values can be read from the sheet the number of runs will be displayed and the Run button show. If not, click on Show Errors to see why it failed to read values.
You can also include a column or row with the header "Run Name" and a list of names you would like to be used for each run. For example:
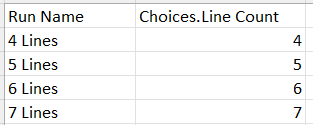
This will make comparative graphs easier to read.
Optimization to run allows you to specify an optimization to be performed for each sensitivity run made. If this is set then the sensitivity parameters for the run will be selected, then an optimization will be performed, and a run will be made using the results of that optimization. Select None to run regular sensitivity analysis.
Note If the optimization set up you have selected has sensitivity set, that setting will be ignored. Similarly, if an optimization is run using a sensitivity setup that references an optimization that reference will be ignored.
Run Termination Criteria allows you to specify conditions under which each sensitivity run will terminate and be removed from the set of runs generated by the sensitivity analysis. Clicking on the button will open the Sensitivity Termination Criteria dialog. This option is only available if you have defined one or more payoffs in the Payoff Specs panel.
Active indicates that this is the sensitivity definition that will be used by the model when sensitivity is run. Only once sensitivity definition will be active at a time. Unchecking this will deactivate sensitivity, so that S-Run will not appear in the toolbar. Clicking the Run button will activate the current definition.
Show Parameters from Last Sensi Run will open the Sensitivity Parameters dialog (Model Only). It is only available is a sensitivity analysis has already been done. It will also only show inputs. To see outputs you must open the dialog from a graph or table.
This performs a sensitivity analysis. This is available once you've specified, at a minimum, the number of runs to make. You can also run sensitivity analysis from the menu or the Run toolbar. If this is not available the button will be labeled Show Issues and clicking on it will provide a message explaining why Run will not work.
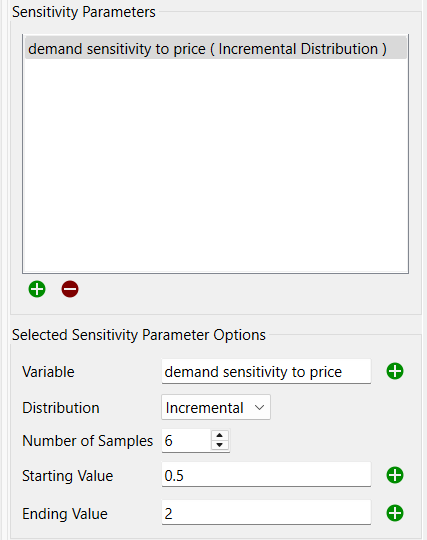
This displays a list of variables to be changed in the sensitivity runs. The list can be empty, normally for those models with equations that use statistical Builtins that have no seed specified. To edit something in the list, click on it. To remove it, click on it and then click on ![]() . To add something to the list, click on
. To add something to the list, click on ![]() and complete the remaining fields.
and complete the remaining fields.
This lets you specify which variable (it has to be a constant converter, a constant flow, or a stock with a constant initial value equation) to use and what values it will take on.
Variable lets you specify which model variable to use. Begin typing (you'll be prompted with autocomplete), drag a variable from the Find dialog, or Ctrl-drag (⌘-drag on Mac) a variable from the model. You can select a single variable or a slice by using * at an array position.
Distribution lets you choose the distribution to be used for the named variable. For more information, see Selecting Sensitivity Analysis Distributions.
The remaining entries in the panel depend on the distribution you've chosen. For all the statistical distributions you can specify a seed, and for some distributions, you can specify additional values. For Ad Hoc, you specify a list. For Incremental, you specify a minimum and a maximum. If you've selected "All combinations" above, there will also be an entry for the Number of Samples for all but the Ad Hoc distribution.
For most parameters you can either type in a number, or select a model variable using the
to the right of the editing box. Any model variable can be used. This allows sensitivity bounds to be set via controlled variable values which can be most useful on the interface. You can use either arrayed or non arrayed variables, and you can use a * in place of a dimension name as long as the same dimension uses a * in the specified sensitivity variable.
Note If you're using random distributions, with all combinations or random sampling be sure to specify a different noise seed for each sensitivity variable (or leave noise seed blank).
Note You can leave noise seed blank to use a different set of values for every sensitivity run.
Note Any errors in the specified parameters can be seen by hovering on the parameter in the Sensitivity Parameters list.